

.svg)

Back to Blog
TechCrunch Impersonation Scams
BY
Aalishan Jami

category
Cloud
READ
15 MIN READ
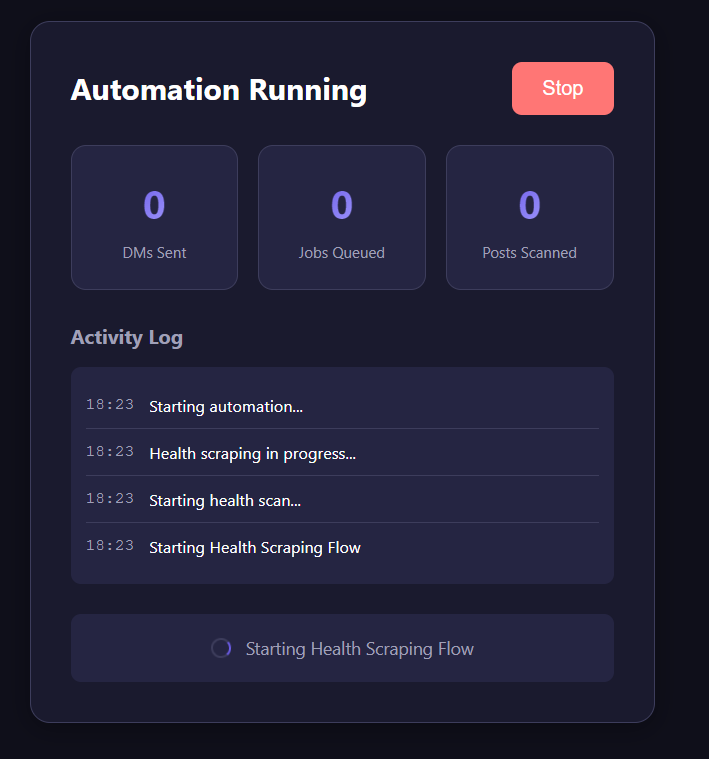
The architecture of modern digital ecosystems is no longer a static blueprint. It has evolved into a living, breathing organism of interconnected services, each requiring a level of precision that traditional engineering frameworks struggle to maintain. As we push toward high-concurrency environments, the concept of "resilience" must be redefined from mere uptime to proactive self-healing. In a world where data is the primary currency, the ability to manage state and statelessness simultaneously becomes the hallmark of a senior architect. This requires a deep understanding of how packets move across a network, how database locks influence latency, and how garbage collection cycles in JavaScript can impact the real-time nature of a Socket.io connection. When building for scale, one must anticipate the failure of every component. It is not a matter of "if" a service will go down, but "when." Therefore, the goal of the developer is to create a system that degrades gracefully, ensuring that a failure in the notification layer does not bring down the entire payment processing engine. This philosophical approach to coding—viewing the codebase as a dynamic, shifting landscape—is what separates a simple coder from a systems engineer. We must obsess over the minutiae of our DTOs and the efficiency of our TypeORM queries to ensure that every byte is accounted for. As we embark on this technical journey, we must maintain a balance between rapid feature deployment and the long-term health of the technical debt we inevitably accrue.
Scaling a system is rarely a linear progression. Instead, it is a series of phase shifts where the very rules that governed the system at a lower magnitude become the primary sources of friction at the next level. We see this most clearly in the transition from monolithic architectures to granular microservices. As the number of nodes in a cluster increases, the complexity of communication grows exponentially. It is no longer enough to have a single source of truth; we must now deal with eventual consistency and the challenges of distributed transactions. This requires a shift in mindset—from designing for ideal conditions to engineering for unpredictability. Systems must be intentionally designed to absorb shocks, adapt in real time, and recover without centralized control. Every line of code added to a scaling system must be scrutinized for its impact on the overall complexity. Simplicity is often discarded in favor of "clever" solutions, but true mastery lies in achieving the desired outcome with the least amount of moving parts. This is especially true in the JavaScript ecosystem, where the abundance of libraries can often lead to "dependency hell." A disciplined developer knows when to write a custom utility and when to rely on a battle-tested framework. By keeping the core logic lean, we reduce the surface area for bugs and performance bottlenecks. Ultimately, the survival of a large-scale application depends on the developer's ability to remain objective and ruthless in the pursuit of architectural purity.
The philosophy behind building a marketplace like FIXIT involves understanding the intersection of human behavior and technical reliability. When a user requests a service, they are not just initiating a database entry; they are engaging in a trust-based transaction that requires millisecond-accurate feedback. This is where the power of NestJS and real-time sockets truly shines. By creating a bi-directional communication channel, we bridge the gap between the digital request and the physical fulfillment of a service. However, this real-time capability introduces new challenges in terms of resource management. Each socket connection consumes memory and CPU cycles, and without proper load balancing and horizontal scaling, the system can quickly become overwhelmed. We must implement robust throttling and rate-limiting strategies to protect the integrity of our API. Furthermore, the geospatial nature of hyperlocal services adds another layer of complexity. Calculating distances in real-time, managing geofences, and ensuring that providers are matched with the nearest customers requires a highly optimized database schema. Every index and every join must be carefully planned. As we look toward the future of the service economy, the integration of AI for predictive matching and dynamic pricing will become standard. To prepare for this, our current architecture must be flexible enough to incorporate machine learning models without requiring a total rewrite of the backend.
"Complexity is not the goal. Simplicity is the byproduct of mastering complexity through architectural discipline."
Systems Manifesto, Vol. IVTo build systems that survive the volatility of global traffic, architects must prioritize three fundamental pillars: stateless execution, observability, and graceful degradation. Stateless execution allows us to spin up or down instances of our application without worrying about session persistence, enabling true horizontal elasticity. This is a requirement for any modern cloud-native application. Observability, on the other hand, moves beyond simple monitoring. It is not enough to know "if" a system is up; we must understand "why" it is behaving in a certain way. This is achieved through high-cardinality telemetry, distributed tracing, and centralized logging. When a request fails, we should be able to trace its journey through every microservice to pinpoint exactly where the failure occurred. Finally, graceful degradation ensures that the system remains functional even when certain components are struggling. By implementing circuit breakers and fallback mechanisms, we can provide a slightly diminished user experience rather than a total blackout. This resilience is what builds user trust over time. In a competitive market, reliability is often the deciding factor for user retention. If a service is consistently available and responsive, users will return; if it is flaky and unpredictable, they will seek alternatives.
Stateless Execution: Decoupling processing from storage allows for infinite horizontal elasticity without the burden of session persistence.
Observability over Monitoring: Moving beyond "is it up?" to "why is it behaving this way?" through high-cardinality telemetry.
Graceful Degradation: Implementing circuit breakers and fallback mechanisms to ensure the whole doesn't fail when a part does.
The technical landscape is constantly shifting, and as developers, we must be committed to continuous learning. The transition from being a JavaScript developer to a systems architect involves more than just mastering a new framework; it requires a change in perspective. We must learn to look at the system as a whole, understanding how the frontend interact with the backend, and how the infrastructure supports both. This holistic view allows us to make better decisions about where to place logic and how to optimize data flow. For instance, deciding whether to perform a specific calculation on the client side or the server side depends on factors like latency, processing power, and data security. By understanding the trade-offs of each approach, we can build more efficient and user-friendly applications. Additionally, we must stay informed about emerging trends and technologies. The rise of serverless computing, edge computing, and decentralized web technologies will continue to reshape how we build and deploy software. Staying ahead of the curve requires a proactive approach to research and experimentation. By constantly challenging our assumptions and testing new ideas, we can ensure that our skills remain relevant in a rapidly evolving industry.
Data integrity and security are the cornerstones of any digital platform, especially one that handles financial transactions and personal information. As we integrate various third-party services for payments and authentication, we must be vigilant about the security implications of these integrations. Every API endpoint must be secured with robust authentication and authorization mechanisms. We must also implement data encryption at rest and in transit to protect sensitive information from unauthorized access. In the context of the FIXIT platform, ensuring the safety of both providers and users is paramount. This involves not only technical security measures but also administrative policies such as background checks and verification processes. By fostering a secure environment, we can build a community of trust that encourages long-term engagement. Furthermore, we must consider the ethical implications of our technology. As we collect and analyze vast amounts of user data, we must be transparent about how this data is used and ensure that we are complying with relevant privacy regulations. Responsible data management is not just a legal requirement; it is a moral obligation.
The user experience (UX) is the final piece of the puzzle. Even the most technically sound backend is useless if the frontend is difficult to navigate or slow to respond. This is where tools like Webflow and GSAP come into play, allowing us to create fluid, engaging interfaces that guide the user through the application. A well-designed UX should be intuitive, accessible, and fast. We must pay close attention to details like loading states, error messages, and micro-interactions, as these small elements can have a significant impact on the overall user experience. By putting ourselves in the shoes of the user, we can identify pain points and areas for improvement. This user-centric approach to development ensures that our technology serves a real need and provides genuine value. In conclusion, building a modern digital ecosystem is a multifaceted challenge that requires a blend of technical expertise, architectural discipline, and a deep commitment to the user. By following the principles of distributed reliability and maintaining a focus on simplicity and security, we can build systems that not only survive but thrive in the face of complexity.
The journey of an engineer is marked by the constant tension between innovation and stability. We are driven by the desire to build new things, yet we are responsible for the maintenance of existing systems. This balance is difficult to strike, but it is necessary for sustainable growth. As we move forward, let us embrace the challenges of scale and complexity, knowing that with the right tools and mindset, we can build a future where technology is a force for good. The path is long, the work is difficult, but the rewards are immense. Precision is the only path forward.
Get started for Free
See what you can achieve
We create secure, AI-driven, data-powered technology solutions that help businesses scale and innovate with confidence.
info@scaylar.com
Pakistan
1st Floor, 15 Khayaban-e-Jinnah, Block A, Opf Housing, Lahore.
+92 320-143-6163
USA
380 McLean Ave, Yonkers, NY 10705, USA
+1 914-574-7419
USA
380 McLean Ave,
Yonkers, NY 10705,
USA
+1 914-574-7419
©2026 Scaylar Technologies. All rights reserved.
©2026 Scaylar Technologies. All rights reserved.